 shadowsocks原理——模块划分
shadowsocks原理——模块划分
没有基础,直接阅读源码,就像是苹果砸到自己头上,然后自己努力推算出万有引力公式。难度太大了,就算能达到目标,也会相当艰难,效率很低。
因此,学习一个工具,需要我们从顶层设计,然后逐步深入剖析,这样,在学习的时候会更容易构建知识网络,既不枯燥,也可以融会贯通。
shadowsocks 项目代码量少,2000 多行。大神们觉得逻辑简单,然而我从 15 年接触,到 23 年,都没能完整阅读 shadowsocks 项目,经常是遇到什么问题,就选择放弃,因为直接生啃源代码,没有一些理论基础,会不明白为什么进行一些操作,一些模型应用广泛,我们往往是直接使用,新手直接看源代码,可能会因为各个模型或者设计模式不太熟悉,就看不懂了。我就是这样。这一次,我记录一下我的探索过程。
首先,ss 的通信流程是在本地建立本地服务器(sslocal),本地所有网络走本地服务器(sslocal)进行代理,本地服务器(sslocal)加密后转发到远程服务器(ssserver),远程服务器(ssserver)验证身份和解密后,转发到目标服务器。目标服务器返回的数据再通过远程服务器(ssserver)加密后传回本地服务器(sslocal),本地服务器(sslocal)解密后,再转发回本地应用程序。
sslocal 和 ssserver 都是采用的 reactor 模型。这里需要积累一下 reactor 模型基础知识,这是架构 sslocal 和 ssserver 的模型,理解了这个模型,才能理解 sslocal 和 ssserver
# reactor 模型
网络框架的设计离不开 I/O 线程模型,线程模型的优劣直接决定了系统的吞吐量、可扩展性、安全性等。目前主流的网络框架几乎都采用了 I/O 多路复用的方案。Reactor 模式作为其中的事件分发器,负责将读写事件分发给对应的读写事件处理者。
大名鼎鼎的 Java 并发包作者 Doug Lea,在 Scalable I/O in Java 一文中阐述了服务端开发中 I/O 模型的演进过程。Netty 中三种 Reactor 线程模型也来源于这篇经典文章.
# 1. IO 进化史
一个网络请求,在服务端经历的阶段:
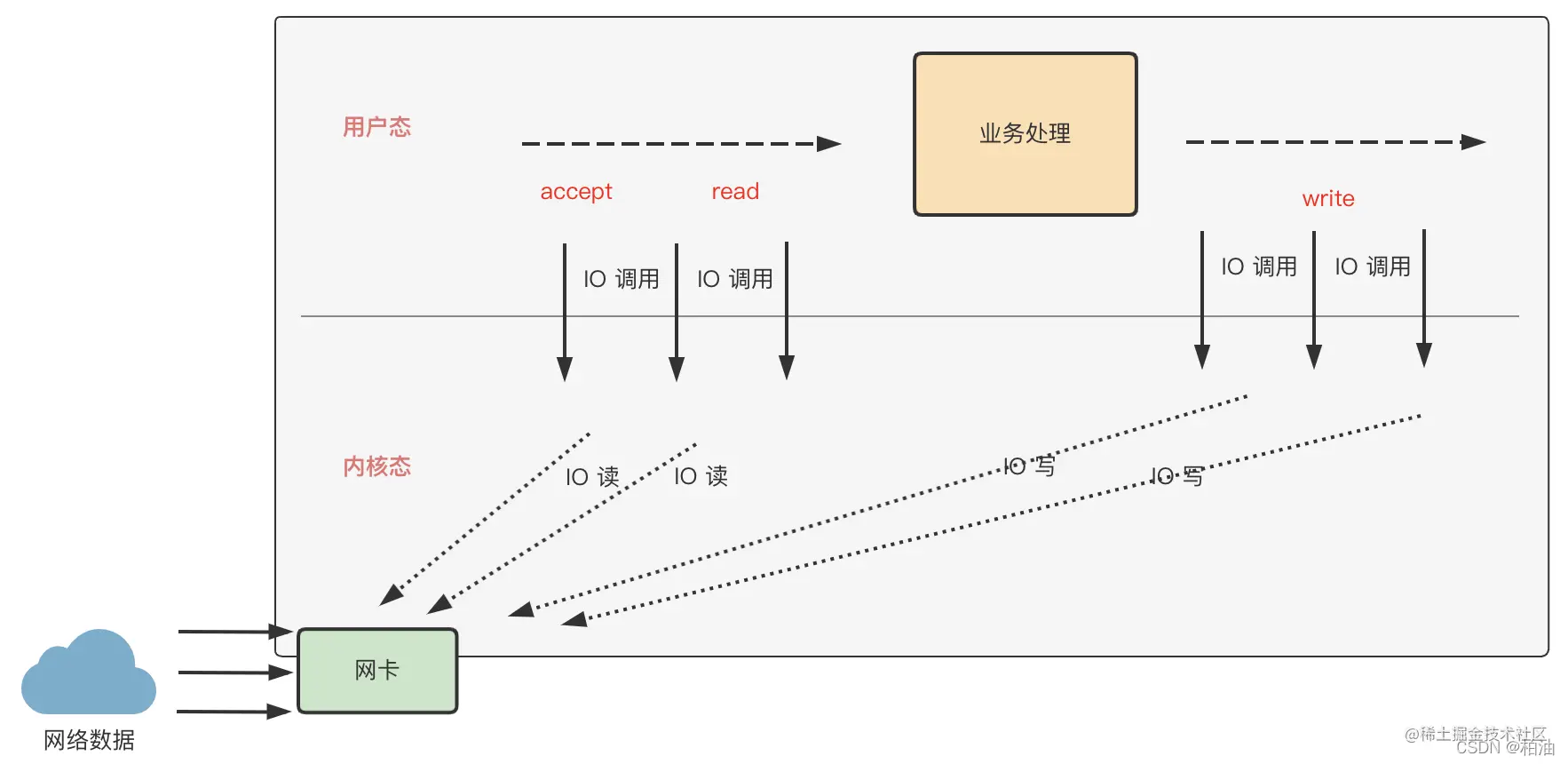
网络请求先后经历服务器网卡、内核、连接建立、数据读取、业务处理、数据写回等一系列过程。
其中,连接建立(accept)、数据读取(read)、数据写回(write)等操作都需要操作系统内核提供的系统调用,最终由内核与网卡进行数据交互,这些 IO 调用消耗一般是比较高的,比如 IO 等待、数据传输等。
最初的处理方式是,每个连接都用独立的一个线程来处理这一系列的操作,即 建立连接、数据读写、业务逻辑处理;这样一来最大的弊端在于,N 个连接就需要 N 个线程资源,消耗巨大。
所以,在网络模型演化过程中,不断的对这几个阶段进行拆分,比如,将建立连接、数据读写、业务逻辑处理等关键阶段分开处理;这样一来,每个阶段都可以考虑使用单线程或者线程池来处理,极大的节约线程资源;同时,又能获得超高性能。
在深入了解之前,需要了解一下四种常见的 IO 模型以及内核提供的 select/poll/epoll 模型
# 四种常见的 IO 模型
IO 模型需要解决的问题
数据读取的实际场景:首先是在用户态发起调用操作,通过系统函数 read()间接的调用系统内核,从网卡读取数据,先将数据读取到内核缓冲区,再由内核缓冲区拷贝到用户态内存缓冲区
在这个过程中,涉及到 cpu 的操作、内存操作、外部物理设备操作;由于三者数据处理速度的巨大差异性,用户读取数据时,采用 用户线程阻塞等待?非阻塞轮询查询并读取数据?还是由内核回调通知?这些便是 I/O 模型要解决的问题
I/O 模型的区别
当用户线程发起 I/O 操作后,网络数据读取操作会经历两个步骤:
- 用户线程等待内核将数据从网卡拷贝到内核空间。
- 内核将数据从内核空间拷贝到用户空间
各种 I/O 模型的区别就是:它们实现这两个步骤的方式是不一样的
4 种主要的 IO 模型
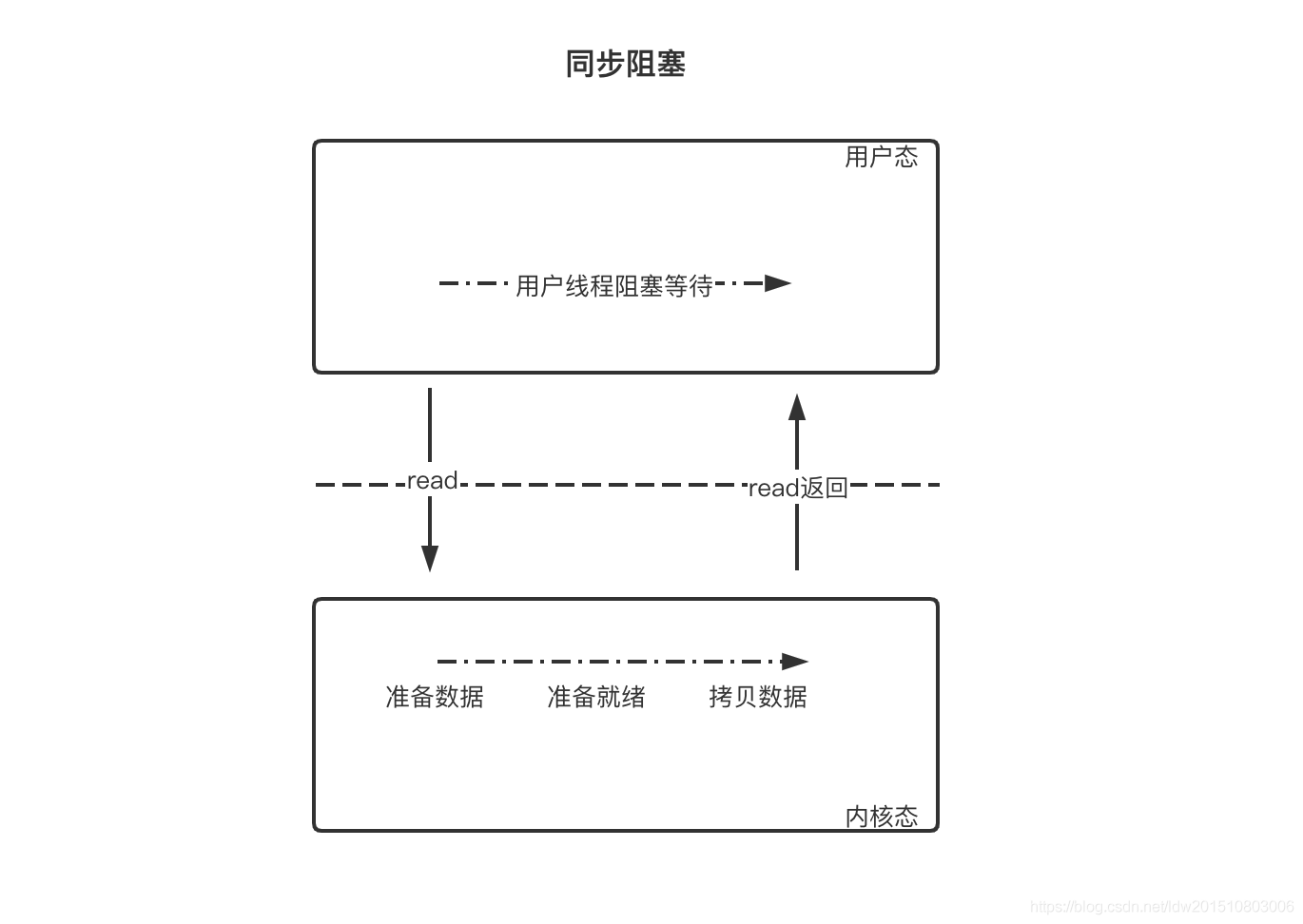
- 同步阻塞
用户线程发起 read 调用后就阻塞了,让出 CPU。内核等待网卡数据到来,把数据从网卡拷贝到内核空间,接着把数据拷贝到用户空间,再把用户线程叫醒
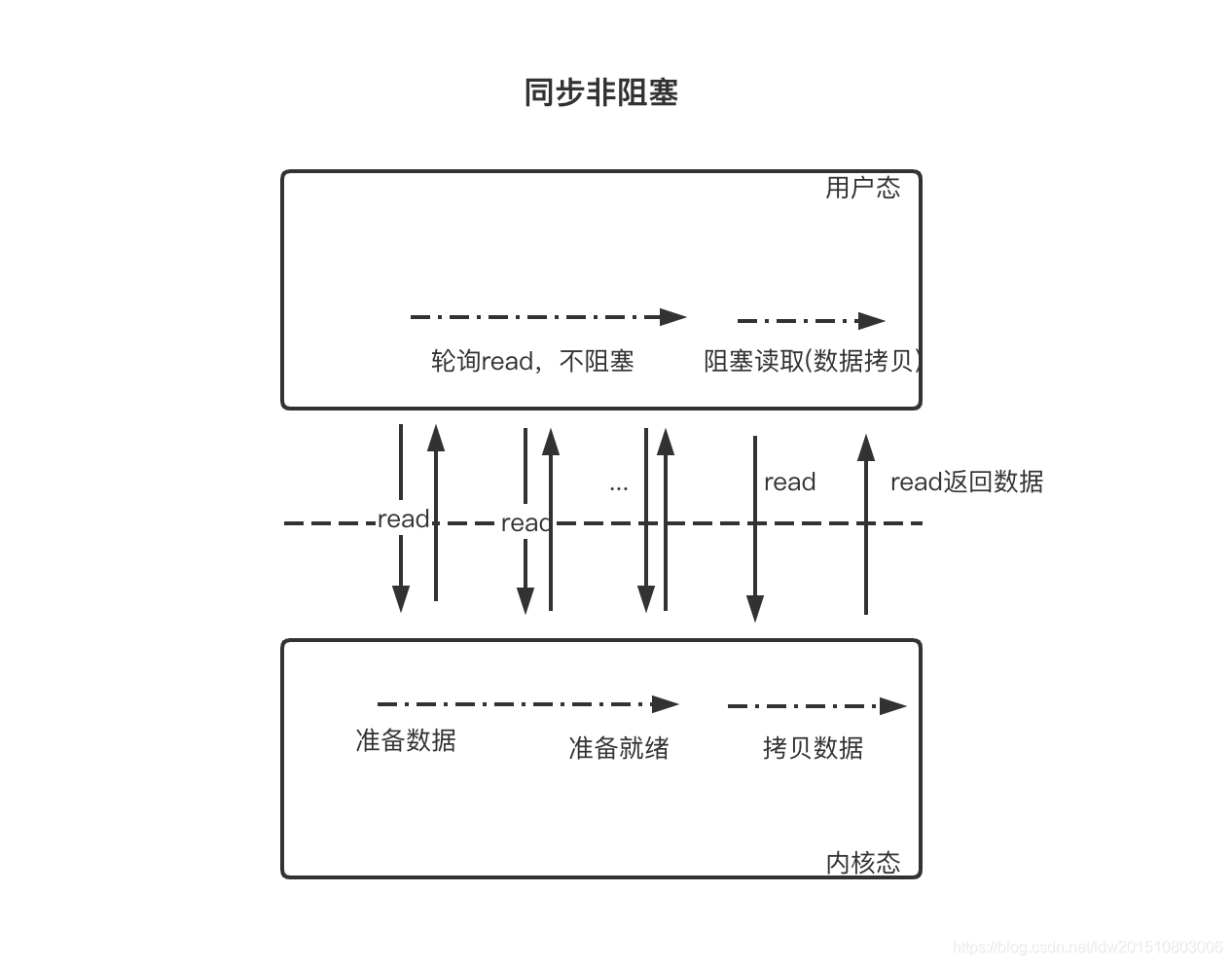
- 同步非阻塞
用户线程不断的发起 read 调用,数据没到内核空间时,每次都返回失败,直到数据到了内核空间,这一次 read 调用后,在等待数据从内核空间拷贝到用户空间这段时间里,线程还是阻塞的,等数据到了用户空间再把线程叫醒
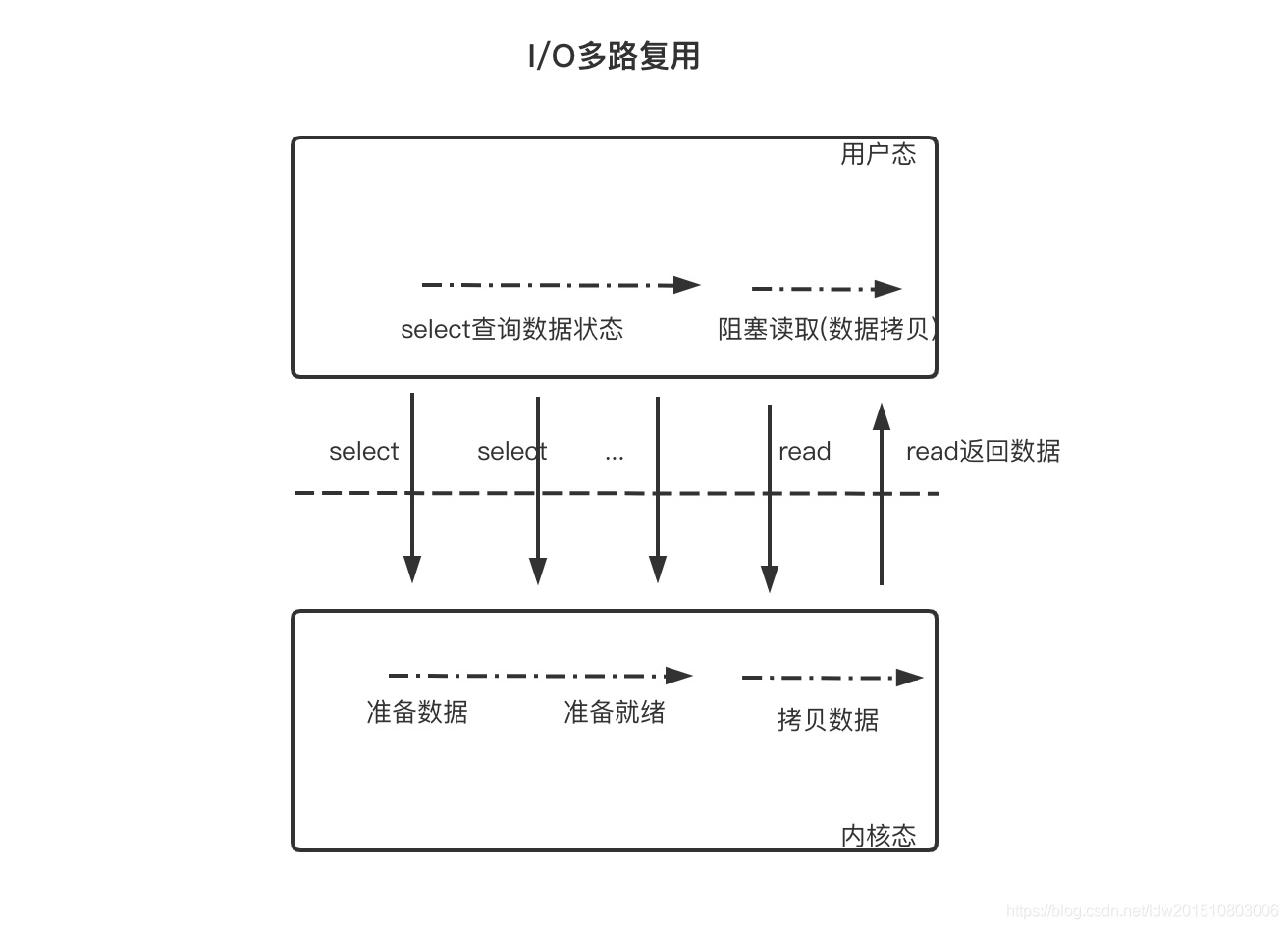
- IO 多路复用
用户线程的读取操作分成两步了,线程先发起 select 调用,目的是问内核数据准备好了吗?等内核把数据准备好了,用户线程再发起 read 调用。在等待数据从内核空间拷贝到用户空间这段时间里,线程还是阻塞的。那为什么叫 I/O 多路复用呢?因为一个专用线程轮询发起 select 调用可以向内核查多个数据通道(Channel)的状态,所以叫多路复用
- 异步 IO
用户线程发起 read 调用的同时注册一个回调函数,read 立即返回,等内核将数据准备好后,再调用指定的回调函数完成处理。在这个过程中,用户线程一直没有阻塞
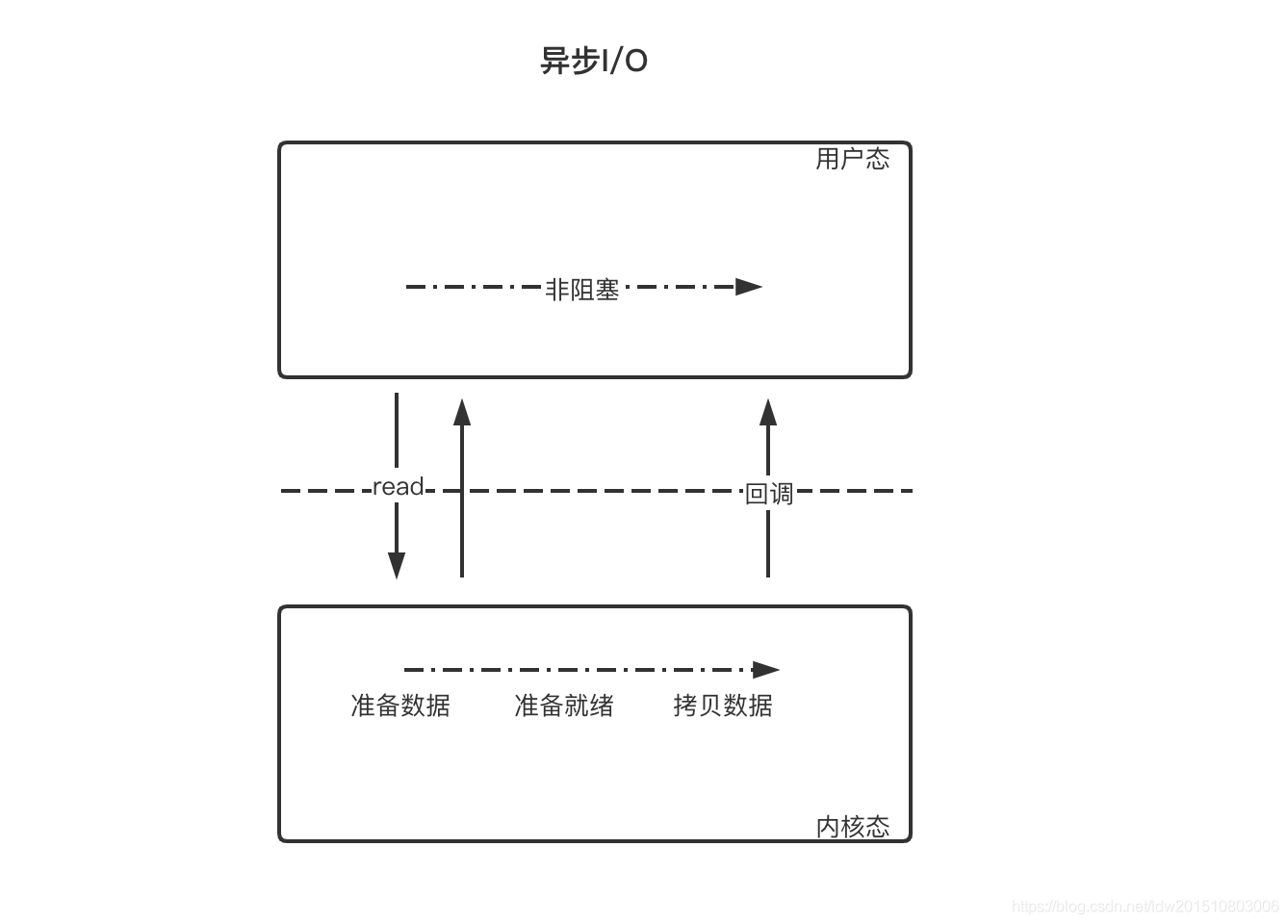
4 种 IO 模型的总结
1、同步非阻塞与 I/O 多路复用区别
相同点:都通过轮询的方式尝试读取数据;不同的是 一个是由用户线程自己不断轮询,另一个是通过专用线程去轮询处理(专用线程数量可控) 同步非阻塞:用户线程不断轮询直到读取数据为止;这个过程中每个用户线程都是轮询读取,如果用户线程过多,耗费资源 I/O 多路复用:一般通过一个专用线程去轮询检查数据是否就绪,由于一个专用线程可以处理多个连接(channel 通道),也就称为 I/O 多路复用;Java NIO 便是 I/O 多路复用的一个实现
2、阻塞与非阻塞:指应用程序在发起 I/O 操作时,是立即返回还是等待
3、同步与异步:指应用程序在与内核通信时,数据从内核空间到应用空间的拷贝,是由内核主动发起还是由应用程序来触发;内核主动发起则是异步,反之为同步
一个线程就可以监听所有网络连接的 IO 事件是否就绪的模式,就是 IO 多路复用
Reactor 模型就是基于 IO 多路复用构建的
非阻塞 NIO 搭配 IO 多路复用机制是高并发的钥匙 libhv 下的 event 模块正是封装了多种平台的 IO 多路复用机制,提供了统一的事件接口,是 libhv 的核心模块。
# 事件驱动
IO 模型是 Reactor 模型的一半,另一半则是事件驱动。事件驱动指的是当 IO 事件准备就绪时,以事件的形式通知相关线程进行数据读写,进而业务线程可以直接处理这些数据,这一过程的后续操作方,都是被动接收通知,看起来有点像回调操作。
这种模式下,IO 读写线程、业务线程工作时,必有数据可操作执行,不会在 IO 等待上浪费资源,这便是事件驱动的核心思想。
# Reactor 模型
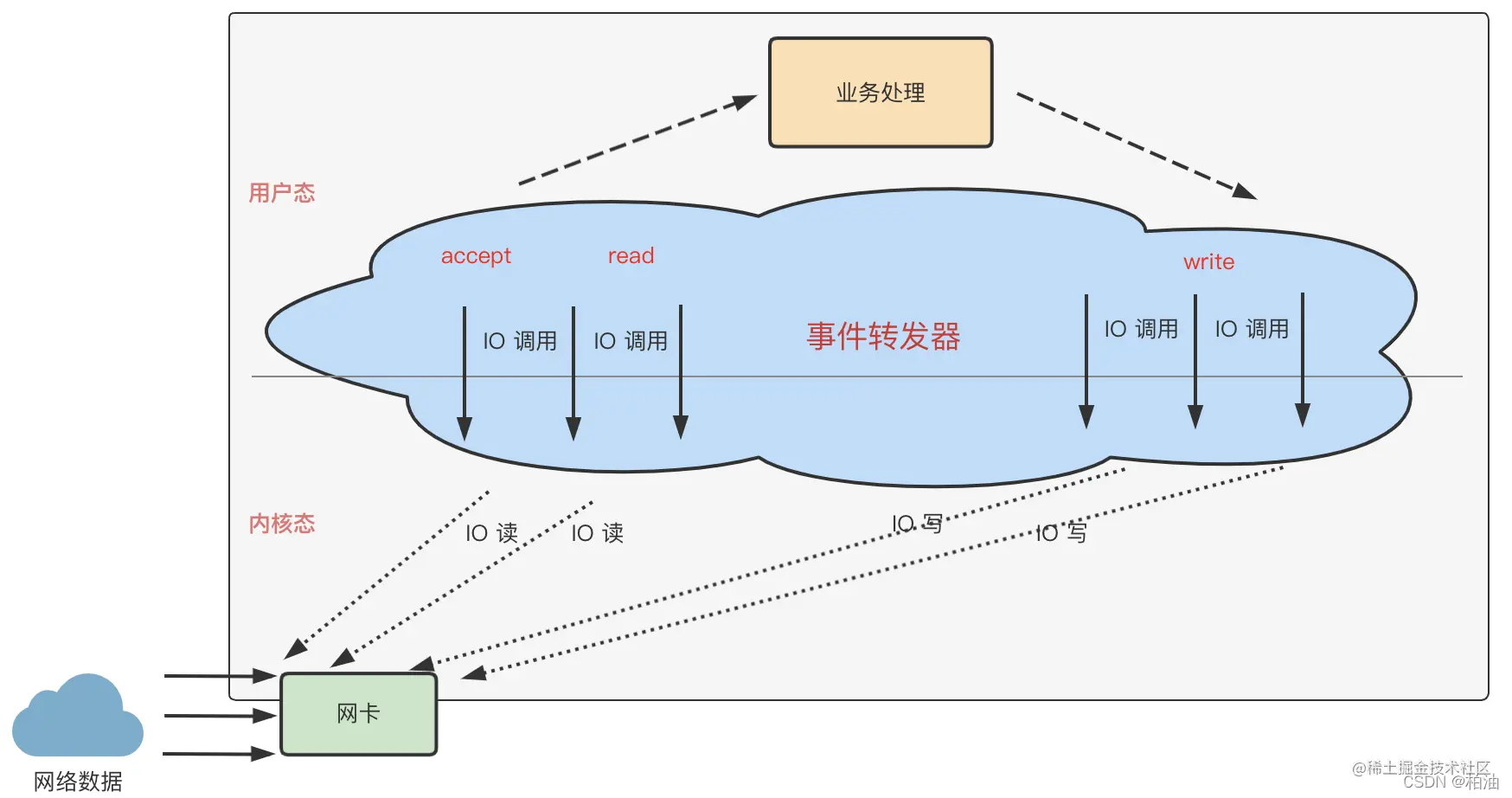 Reactor 模型的核心是事件驱动,Reactor 模型种的反应器角色(Reactor 线程)类似于事件转发器,承接事件建立、IO 处理、事件分发的任务。
Reactor 模型的核心是事件驱动,Reactor 模型种的反应器角色(Reactor 线程)类似于事件转发器,承接事件建立、IO 处理、事件分发的任务。
Reactor 模式由 Reactor 线程、Handlers 处理器两大角色组成,两大角色的职责分别如下:
- Reactor 线程的职责:主要负责连接建立、监听 IO 事件、IO 事件读写以及将事件分发到 Handlers 处理器。
- Handlers 处理器(业务处理)的职责:非阻塞的执行业务处理逻辑。
# Reactor 三种方式
Reactor 模型在不同阶段都有相关的优化策略,常见的有以下三种方式呈现:
- 单线程模型
- 多线程模型
- 主从多线程模型
多线程 Reactor 的演进分为两个方面:
- 升级 Handler。既要使用多线程,又要尽可能高效率,则可以考虑使用线程池。
- 升级 Reactor。可以考虑引入多个 Selector(选择器),提升选择大量通道的能力。
# 单线程模型
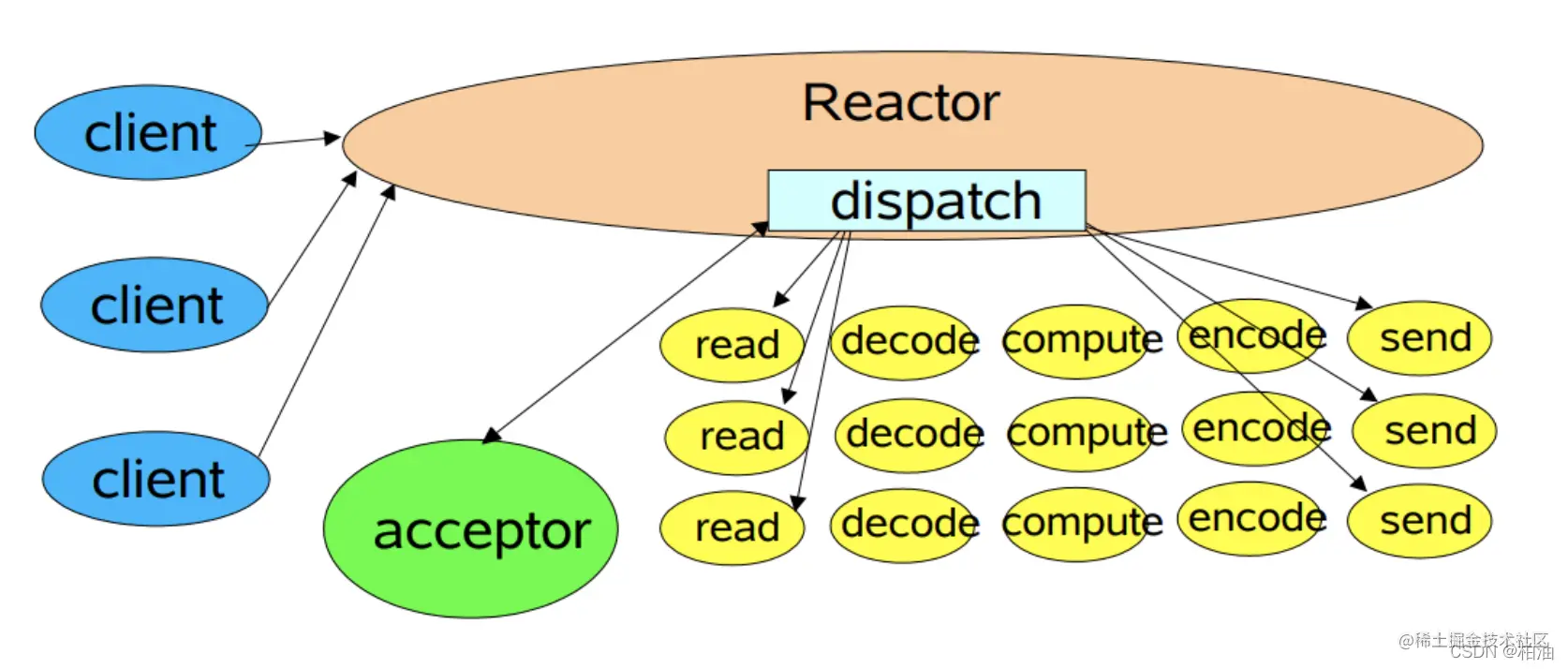
上图描述了 Reactor 的单线程模型结构,在 Reactor 单线程模型中,所有 I/O 操作(包括连接建立、数据读写、事件分发等)、业务处理,都是由一个线程完成的。单线程模型逻辑简单,缺陷也十分明显:
一个线程支持处理的连接数非常有限,CPU 很容易打满,性能方面有明显瓶颈;
当多个事件被同时触发时,只要有一个事件没有处理完,其他后面的事件就无法执行,这就会造成消息积压及请求超时;
线程在处理 I/O 事件时,Select 无法同时处理连接建立、事件分发等操作;
如果 I/O 线程一直处于满负荷状态,很可能造成服务端节点不可用。
在单线程 Reactor 模式中,Reactor 和 Handler 都在同一条线程中执行。这样,带来了一个问题:当其中某个 Handler 阻塞时,会导致其他所有的 Handler 都得不到执行。
在这种场景下,被阻塞的 Handler 不仅仅负责输入和输出处理的传输处理器,还包括负责新连接监听的 Acceptor 处理器,可能导致服务器无响应。这是一个非常严重的缺陷,导致单线程反应器模型在生产场景中使用得比较少。
# 多线程模型
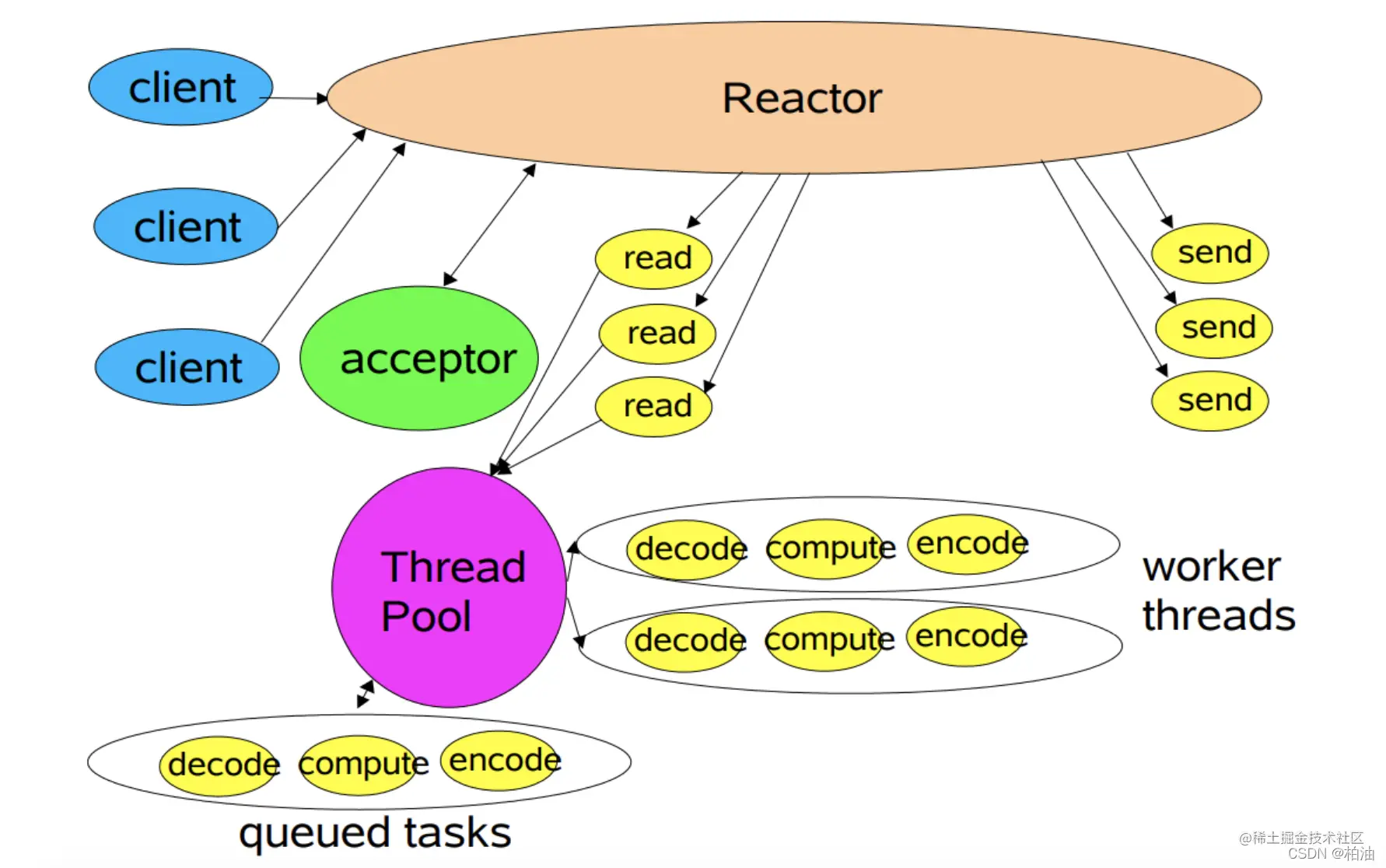
由于单线程模型有性能方面的瓶颈,多线程模型作为解决方案就应运而生了。
Reactor 多线程模型将业务逻辑交给多个线程进行处理。除此之外,多线程模型其他的操作与单线程模型是类似的,比如连接建立、IO 事件读写以及事件分发等都是由一个线程来完成。
当客户端有数据发送至服务端时,Select 会监听到可读事件,数据读取完毕后提交到业务线程池中并发处理。
一般的请求中,耗时最长的一般是业务处理,所以用一个线程池(worker 线程池)来处理业务操作,在性能上的提升也是非常可观的。
当然,这种模型也有明显缺点,连接建立、IO 事件读取以及事件分发完全有单线程处理;比如当某个连接通过系统调用正在读取数据,此时相对于其他事件来说,完全是阻塞状态,新连接无法处理、其他连接的 IO 查询/IO 读写以及事件分发都无法完成。
对于像 Nginx、Netty 这种对高性能、高并发要求极高的网络框架,这种模式便显得有些吃力了。因为,无法及时处理新连接、就绪的 IO 事件以及事件转发等。
接下来,我们看看主从多线程模型是如何解决这个问题的。
# 主从多线程模型
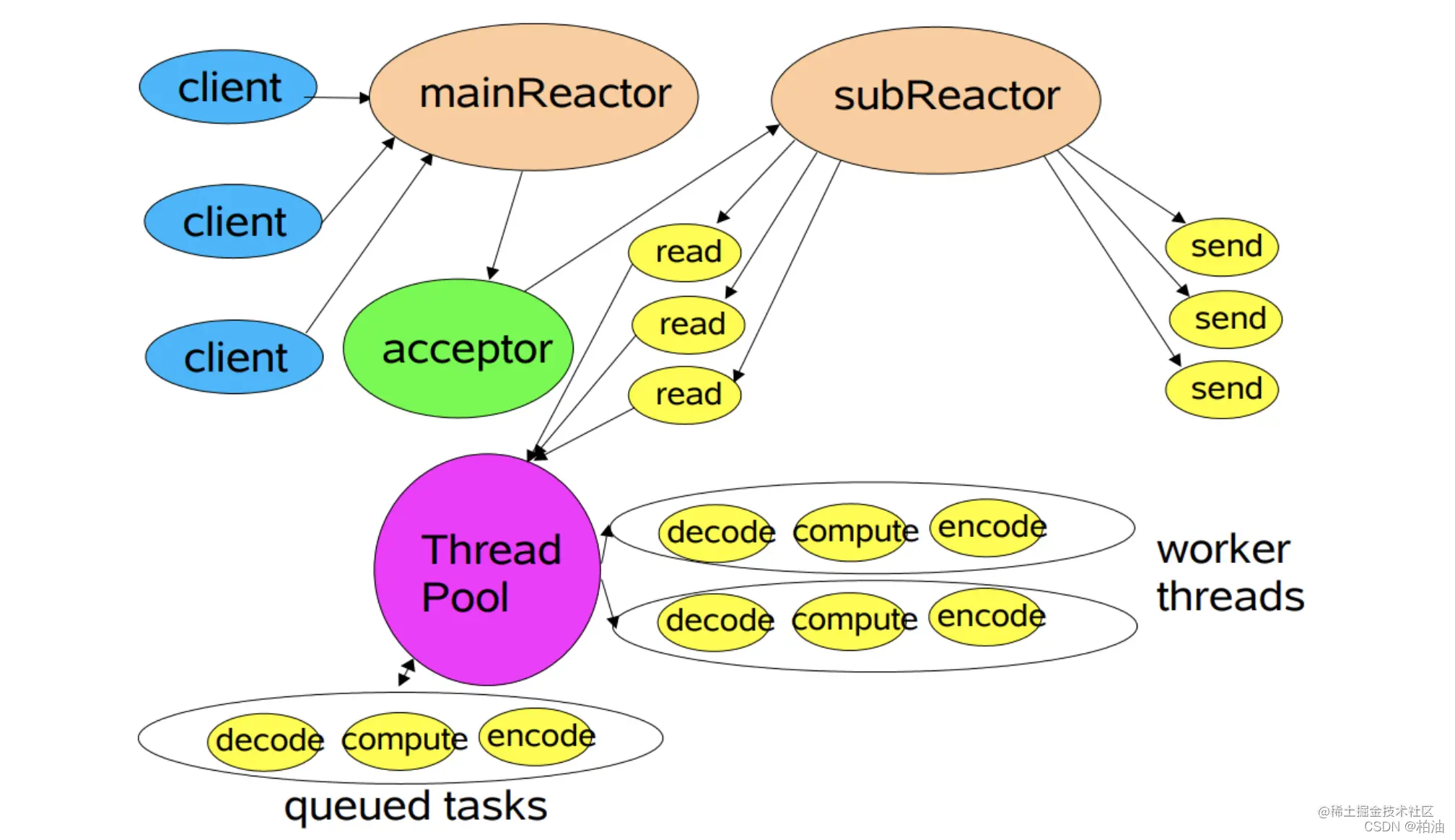
在多线程模型中,我们提到,其主要缺陷在于同一时间无法处理大量新连接、IO 就绪事件。因此,将主从模式应用到这一块,就可以解决这个问题。
主从 Reactor 模式中,分为了主 Reactor 和 从 Reactor,分别处理 新建立的连接、IO读写事件/事件分发。
一来,主 Reactor 可以解决同一时间大量新连接,将其注册到从 Reactor 上进行 IO 事件监听处理
二来,IO 事件监听相对新连接处理更加耗时,此处我们可以考虑使用线程池来处理。这样能充分利用多核 CPU 的特性,能使更多就绪的 IO 事件及时处理。
简言之,主从多线程模型由多个 Reactor 线程组成,每个 Reactor 线程都有独立的 Selector 对象。MainReactor 仅负责处理客户端连接的 Accept 事件,连接建立成功后将新创建的连接对象注册至 SubReactor。再由 SubReactor 分配线程池中的 I/O 线程与其连接绑定,它将负责连接生命周期内所有的 I/O 事件。 在海量客户端并发请求的场景下,主从多线程模式甚至可以适当增加 SubReactor 线程的数量,从而利用多核能力提升系统的吞吐量。